Trainer Engine
Predict molecular properties and boost the efficiency of machine learning workflows.
Try it free

Download
Benefits
Why you need Trainer Engine
Complete
From input data to implementation of validated models.
Smart
Chemical structure normalization, high-quality and customizable descriptors.

Convenient
Rich feedback and visualization for model optimization.
Reproducible
Central model repository to support selecting production grade models.
Integrable
Access to predictions from a built-in graphical interface, Design Hub or other design platforms.
Predictive
Successful models built on bio-activity, ADMET and phys-chem targets.

Features
Machine learning
Trainer Engine offers automatized, high performant, and configurable descriptor generation on normalized chemical data. It provides a wide range of machine learning algorithms including Random Forest, Gradient Boosted Trees, Support Vector Machine, and Logistic Regression. Model performance is automatically evaluated, and the most important statistical parameters are calculated both for regression and classification cases.
Feature selection is supported by seamless re-training, based on feature importance in the case of Random Forest. Calibrated error is calculated using the conformal prediction framework. Applicability domain assessment is enabled by returning the most similar structures and corresponding activity data from the training set.
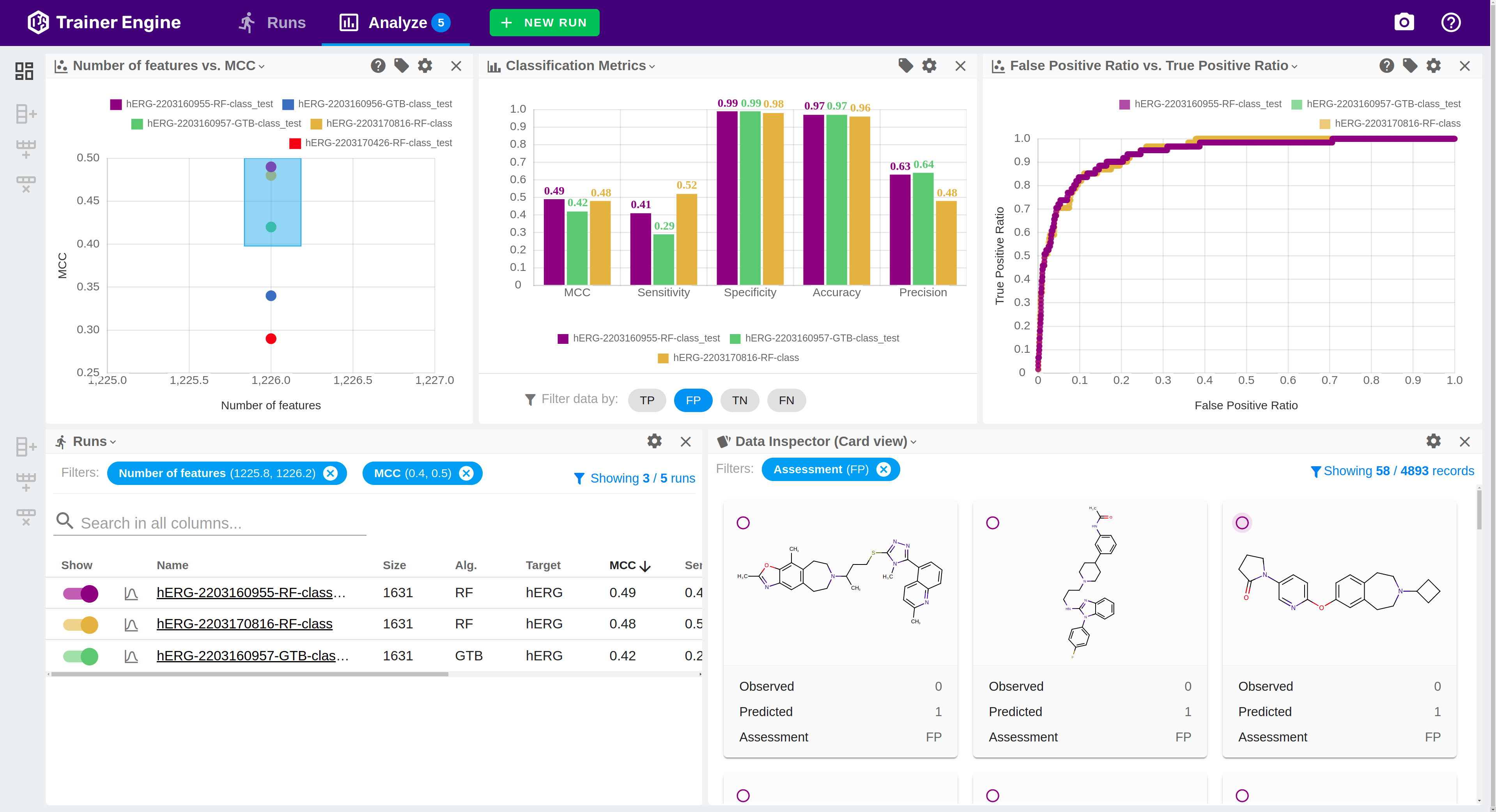
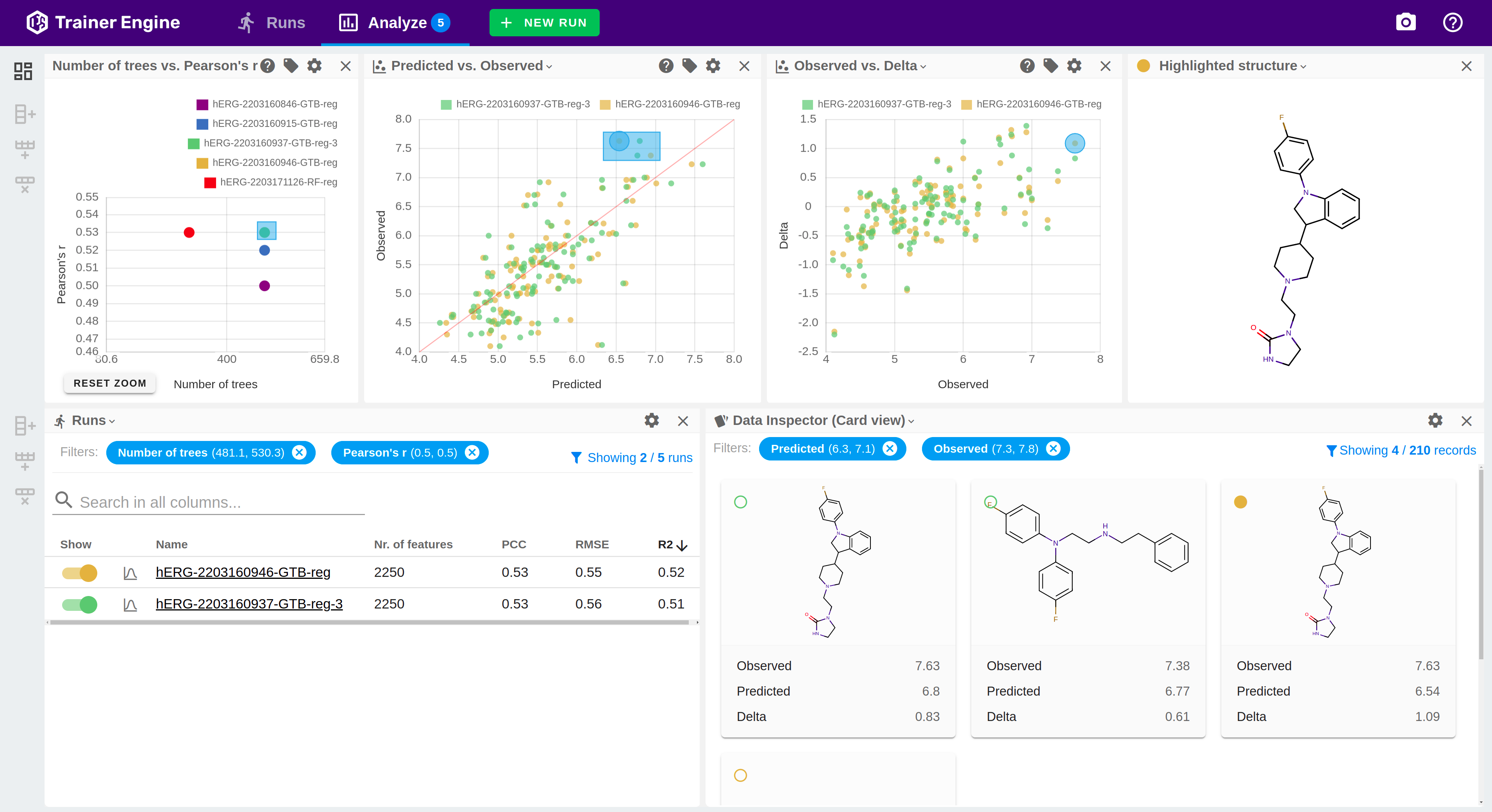
Features
Visualization
The collection of generated models is accessible from the central service in order to benchmark their prediction power and provide insights into their behavior. Trainer Engine stores the models in a repository to ensure reproducibility and comparison of their parameters conveniently. The configurable analysis view comes with a classification and a regression layout presets with optimized tables, charts and molecule visualizations.
Singe / batch mode
Trainer Engine provides services for novel predictions in single or batch mode (through SDF file upload).

REST API
For programmatic access, we recommend using the REST API interface to automatize the machine learning workflow and integrate predictions into design tools like Design Hub or other third-party applications.

Optimized for model building
Trainer Engine graphical user interface offers a rich set of tools to build, validate and compare models. It is loved by computational chemists.

Simple prediction interface
It comes with a lightweight prediction application optimized for end-users, the Playground.